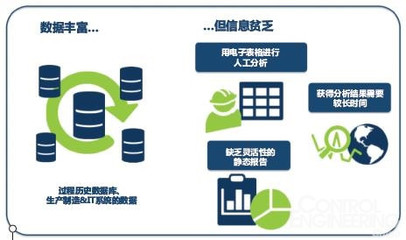
在當今數據驅動的決策環境中,過程數據——即記錄系統、工作流或操作中連續事件的數據——已成為優化效率、預測維護和提升性能的關鍵。處理這種時序性、高頻率且往往體量龐大的數據,需要專門的技術與工具。本文將系統性地介紹探索與分析過程數據的最佳工具鏈,涵蓋從采集、存儲、處理到可視化與分析的各個環節。
1. 數據采集與傳輸
過程數據的探索始于高效可靠的采集。工業物聯網(IIoT)場景中,OPC UA(開放平臺通信統一架構)是實時獲取機器與傳感器數據的行業標準協議,工具如KEPServerEX提供了強大的連接能力。對于日志流數據,Fluentd和Logstash是輕量級且靈活的收集引擎,能夠統一來自多種源的數據并轉發至下游。在云原生環境中,Apache Kafka作為分布式事件流平臺,擅長處理高吞吐量的實時數據流,確保數據可靠傳輸,是構建實時流水線的核心。
2. 數據存儲與管理
原始過程數據通常需要存儲以供歷史查詢與回溯分析。時序數據庫(TSDB)為此類數據量身定制,它們高效壓縮存儲時間戳-指標對。InfluxDB以其易用性和高性能查詢著稱,特別適合監控和物聯網應用;Prometheus則與Kubernetes生態緊密集成,是云原生監控的事實標準。對于需要處理超大規模數據集或復雜分析的場景,Apache Druid能提供低延遲的查詢,而ClickHouse則在分析型查詢速度上表現卓越。若數據需與業務數據關聯,現代數據湖如Delta Lake或Apache Iceberg atop對象存儲(如AWS S3),提供了經濟高效且支持ACID事務的存儲方案。
3. 數據處理與計算
清洗、轉換和聚合過程數據是提取價值的關鍵步驟。Apache Spark Structured Streaming和Apache Flink是處理流數據的頂級框架。Spark擁有豐富的生態系統和易用的API,適合批流一體處理;Flink則在事件時間處理、狀態管理和低延遲方面更勝一籌,是實現復雜事件處理(CEP)的理想選擇。對于更輕量或準實時的轉換,Apache Kafka自身的Kafka Streams API允許在流數據上直接構建應用。在Python數據科學棧中,Pandas(用于批處理)和Streamz(用于流處理)也是探索性分析的得力助手。
4. 數據分析與建模
深入分析需要統計與機器學習工具。Python是這一領域的主導語言,其庫生態無與倫比:NumPy/Pandas用于數據操作,SciPy用于科學計算,scikit-learn提供傳統機器學習算法。對于深度學習或更復雜的模式識別(如異常檢測),TensorFlow和PyTorch是首選。R語言在統計分析與可視化方面依然強大。值得注意的是,許多時序數據庫(如InfluxDB)和可視化平臺(見下文)已內置了基本的異常檢測和預測功能,降低了分析門檻。
5. 數據可視化與監控
將過程數據轉化為直觀見解至關重要。Grafana是監控和可視化領域的明星,它支持多種數據源(尤其是時序數據庫),能輕松創建豐富的儀表盤來實時展示指標、趨勢和警報。對于更復雜的業務智能(BI)和交互式分析,Tableau、Power BI和Superset(開源)能夠連接多種數據源,允許用戶通過拖拽方式進行深度探索。在工業領域,SCADA系統和制造執行系統(MES)通常提供專用的過程可視化界面。
6. 端到端平臺與云服務
為了簡化管理,許多組織選擇集成平臺或云服務。公有云提供商(AWS, Azure, GCP)提供了從物聯網核心到數據倉庫、流處理及AI服務的全托管套件,例如AWS IoT Core + Kinesis + SageMaker。在開源領域,Apache IoTDB是一個集采集、存儲、分析和可視化于一體的物聯網原生時序數據管理系統。
選擇工具的核心考量
選擇最佳工具并非追求功能最全,而需綜合考慮:
- 數據特性:體積、速度、多樣性(是否為純數值時序,或包含事件日志)。
- 延遲要求:是實時監控(亞秒級)、近實時分析(分鐘級)還是批處理。
- 團隊技能:現有技術棧與專業知識(如Java/Scala vs Python)。
- 成本與可擴展性:開源方案與商業軟件、云服務的總擁有成本。
- 生態集成:工具是否能與現有系統平滑銜接。
###
探索過程數據是一個從數據管道到智能洞察的連貫旅程。最佳實踐往往是組合使用上述工具,構建一個健壯、可擴展且高效的棧。例如,一個典型的現代架構可能采用Kafka進行數據流緩沖,Flink進行實時清洗與聚合,InfluxDB存儲明細數據,Grafana進行可視化,并最終利用PySpark或云機器學習服務進行高級分析與模型部署。關鍵在于明確業務目標,從痛點出發,循序漸進地選擇和集成最適合的工具,從而充分釋放過程數據中蘊藏的寶貴價值。